
La nueva hornada de IPs de SiFive llega pisando fuerte y con vocación de abarcarlo todo: desde el IoT y la robótica hasta el corazón de los centros de datos. La compañía presenta la segunda generación de su familia Intelligence con cinco piezas clave: X160 Gen 2, X180 Gen 2, X280 Gen 2, X390 Gen 2 y XM Gen 2, todas ellas basadas en la arquitectura RISC-V y con el foco puesto en cargas de IA modernas.
No es casualidad que esta actualización se haya dado a conocer en un foro de referencia como AI Infra Summit: el mercado empuja hacia soluciones más configurables, escalables y eficientes, y SiFive responde integrando motores escalar, vectorial y matricial bajo una misma estrategia. Además, la firma busca recortar tiempos y costes de diseño con bloques IP bien acoplados y nuevas interfaces de coprocesador optimizadas para acelerar el desarrollo.
Qué aporta la segunda generación de SiFive Intelligence
En esta entrega, SiFive refina su fórmula combinando flexibilidad y rendimiento por vatio. La familia Intelligence Gen 2 consolida un enfoque de cómputo heterogéneo que integra núcleos escalares potentes con vectores RVV 1.0 y, en el caso de XM, un motor matricial propio, todo ello con una estrategia de memoria pensada para exprimir el ancho de banda y reducir cuellos de botella.
La compañía mantiene su filosofía de diseño modular y añade dos vías de acoplamiento de aceleradores: la Vector Coprocessor Interface Extension (VCIX) y la Scalar Coprocessor Interface (SSCI). Estas interfaces permiten a los aceleradores acceder directamente a registros de la CPU, simplificando el software, reduciendo la latencia y mejorando la eficiencia de datos cuando se integran coprocesadores externos o motores especializados.
Con el telón de fondo de unas previsiones que, según Deloitte, anticipan un crecimiento de los workloads de IA del 20% en todos los ámbitos tecnológicos y de hasta un 78% en edge computing, el movimiento de SiFive tiene mucho sentido. El objetivo es ofrecer piezas listas para licenciar que permitan a OEMs y proveedores cloud armar plataformas de IA modulables y preparadas para el futuro.
Además del hardware, la compañía da un paso importante en el ecosistema software: para acelerar el time-to-market, SiFive está liberando como código abierto su SiFive Kernel Library. Esta iniciativa complementa el diseño de las interfaces VCIX/SSCI y apunta a un desarrollo de pilas de IA más rápido y menos costoso.
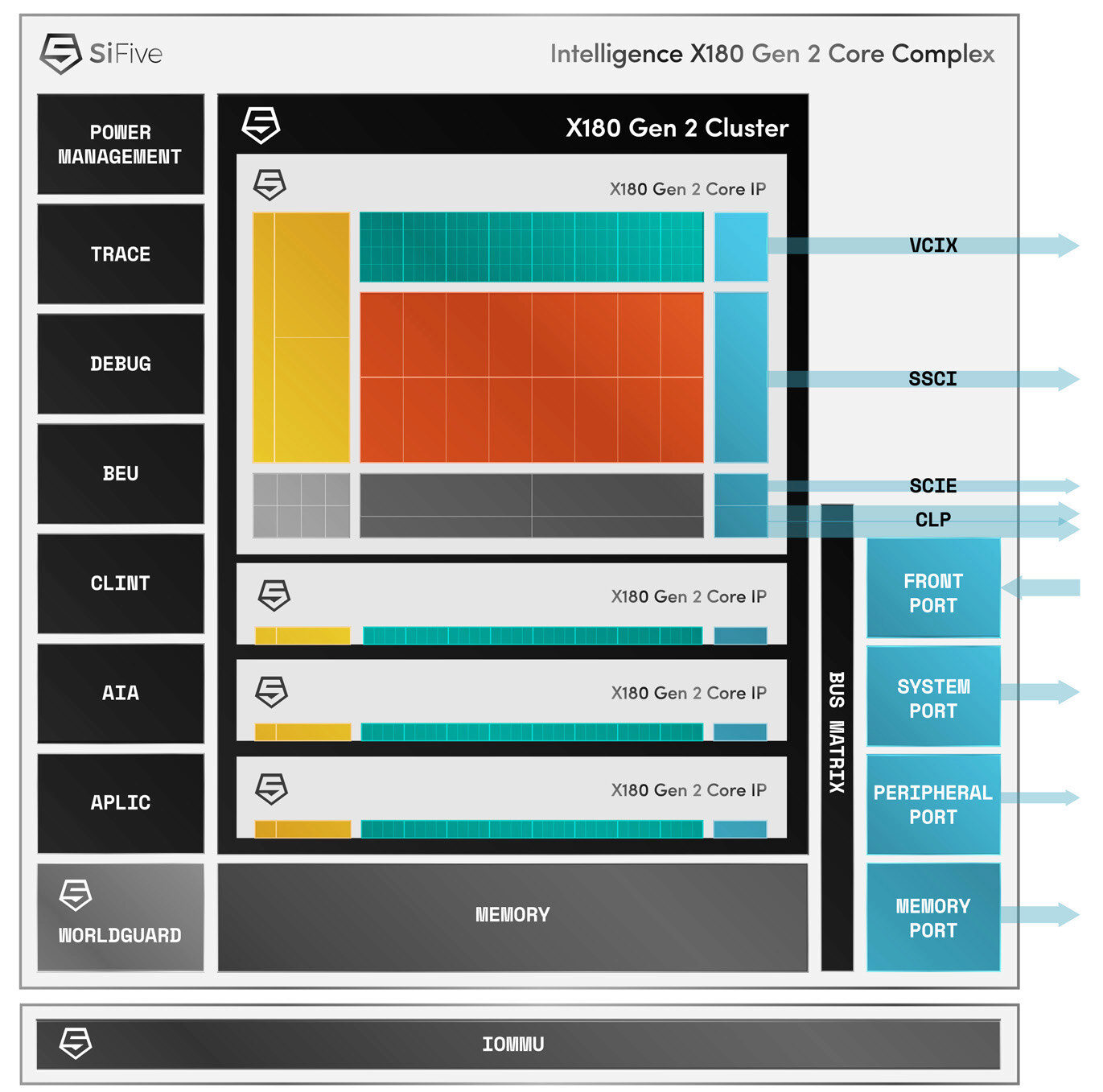
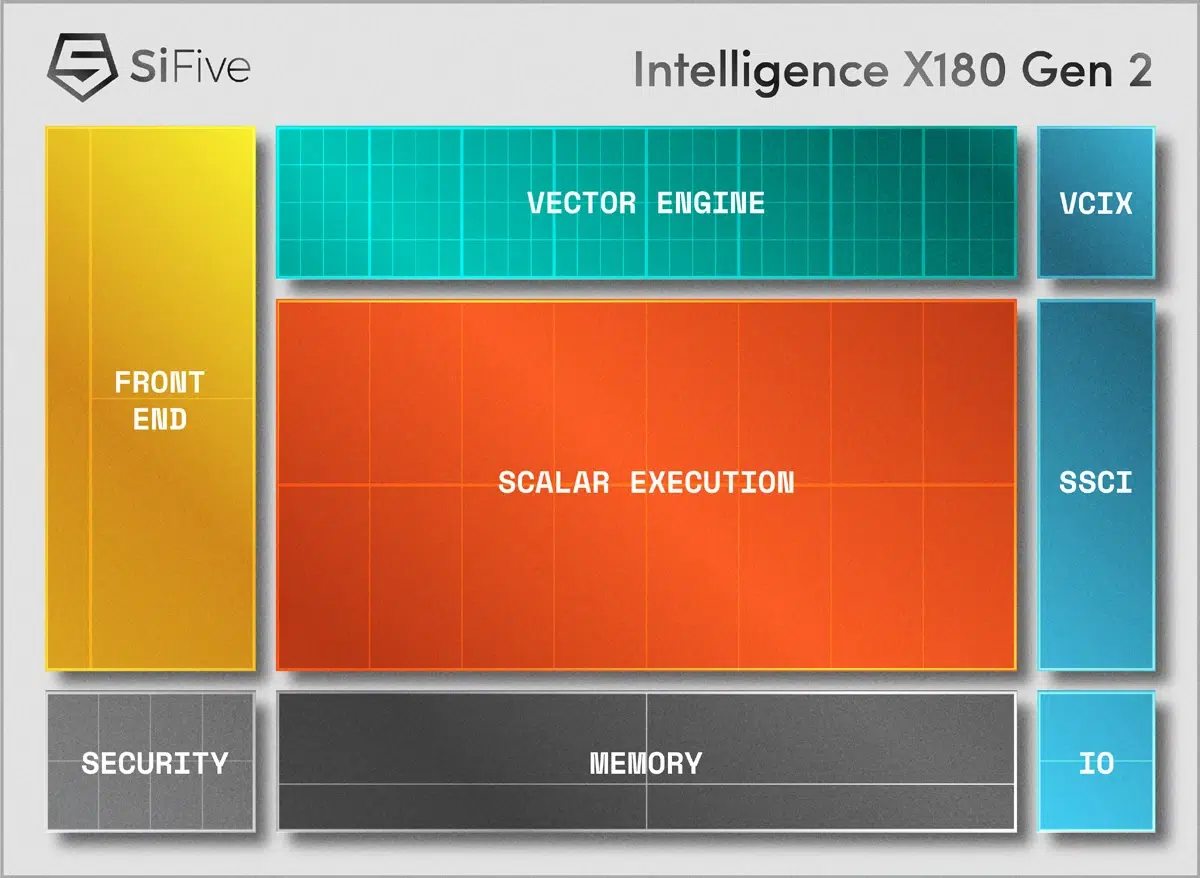
X160 y X180 Gen 2: eficiencia para el edge y el IoT
Los nuevos X160 Gen 2 (32 bits) y X180 Gen 2 (64 bits) están pensados para escenarios con restricciones de energía y espacio como dispositivos IoT, drones y robótica autónoma. Comparten el soporte de registros vectoriales de 128 bits y un camino de datos de 64 bits, lo que les permite ejecutar de forma eficiente formatos numéricos populares en IA como INT8 y BF16.
En términos de escalado, ambos pueden agruparse en clusters de hasta cuatro núcleos, con lo que se consigue un equilibrio muy atractivo entre rendimiento y consumo. Este enfoque permite adaptar la potencia a cada caso de uso sin renunciar a la eficiencia energética que demanda el edge.
El hecho de que integren vectores de 128 bits en esta gama “ligera” pone de manifiesto la intención de SiFive: llevar el cómputo de IA verdaderamente útil a sensores, controladores y robots que operan con baterías o presupuestos térmicos ajustados, sin penalizar el coste ni la superficie de silicio.
Para aplicaciones que necesitan procesar visión artificial, clasificación de señales o control inteligente, estos núcleos ofrecen el conjunto justo de prestaciones vectoriales con una ruta de datos generosa (64 bits) y compatibilidad con tipos de precisión reducida que marcan la diferencia en inferencia.
X280 Gen 2: vectorización madura y optimizada para el borde
La serie X280 ya venía de una primera generación con muy buena adopción en AI/ML, y la revisión X280 Gen 2 redobla la apuesta para el edge con una microarquitectura de 8 etapas, doble emisión, in-order y de tipo superscalar. Este núcleo es multi-core capable y está afinado para computación de IA/ML en el borde con extensiones vectoriales amplias, pensadas para RVV 1.0 y las propias SiFive Intelligence Extensions.
En concreto, el X280 Gen 2 ofrece procesamiento vectorial con VLEN de 512 bits y DLEN de 256 bits, una configuración que permite paralelizar de manera efectiva operaciones típicas de visión, audio y modelos ligeros. Este ancho vectorial, junto a las extensiones específicas de SiFive, acelera los kernels críticos que marcan el rendimiento de aplicaciones reales.
Otro cambio clave es la simplificación de la jerarquía de memoria: se elimina la capa de caché L3 a favor de un L2 compartido de hasta 1 MB por cluster. Con esta decisión, SiFive busca reducir latencias y complejidad, apostando por una caché L2 más grande y flexible que beneficia especialmente a workloads de inferencia con conjuntos de trabajo medianos.
En el plano de la ISA, la nueva remesa adopta RVA23, que introduce soporte nativo para formatos emergentes en IA como BF16, MXFP8 y MXFP4. Este último ha sido elegido recientemente por OpenAI para la distribución de modelos open‑weight, lo cual subraya la importancia de ofrecer tipos de datos compactos con buena fidelidad en inferencias a gran escala.
Con su capacidad multi‑núcleo y su orientación al borde, el X280 Gen 2 encaja en móvil, infraestructura y automoción, campos donde ya triunfó su primera generación. Para quienes necesiten combinar latencias bajas con un perfil de consumo ajustado, resulta una base muy sólida para aplicaciones embebidas de IA.
X390 Gen 2: cuando importa exprimir cada vector
Para escenarios que demandan más músculo vectorial, el X390 Gen 2 da un salto notable respecto al X280 original: con un único núcleo ya aporta una mejora 4× en cómputo vectorial gracias a duplicar la longitud de vector y sumar dos ALUs vectoriales trabajando en paralelo.
Arquitectónicamente, también es un diseño de 8 etapas, doble emisión, in‑order y superscalar, pero aquí se incorporan dos unidades vectoriales con VLEN de 1024 bits y DLEN de 512 bits. El resultado es una plataforma que acelera de forma contundente operaciones intensivas en ancho de vector, abriendo la puerta a modelos y kernels más exigentes.
El X390 Gen 2 es escalable hasta complejos coherentes de 4 núcleos, y puede incorporar de manera opcional la interfaz VCIX para acoplar muy de cerca aceleradores de IA diseñados por el cliente u otros coprocesadores. Esta cercanía reduce la sobrecarga de comunicación y facilita integrar motores externos sin “peajes” de software innecesarios.
En configuraciones de cuatro núcleos, SiFive habla de alcanzar hasta 1 TB/s de ancho de banda efectivo, una cifra que coloca a X390 Gen 2 como candidato idóneo tanto para actuar como Accelerator Control Unit (ACU) como para ejercer de motor de IA autónomo. Esta versatilidad permite construir desde pilas de aceleración híbrida hasta pipelines puros de IA sobre RISC‑V.
No es casual que los diseños X280 y X390 hayan encontrado sitio en proyectos de grandes tecnológicas: ya se han visto en aplicaciones de compañías como Google en sus TPU, donde la simbiosis entre control, pre/post‑proceso y aceleración dura es clave para el rendimiento de producción.
XM Gen 2: el bloque matricial que escala al datacenter
La serie XM Gen 2 representa el “bloque gordo” para cargas de entrenamiento ligero e inferencia a gran escala: integra cuatro núcleos X390 Gen 2 junto a un motor de cómputo matricial desarrollado por SiFive. Esta combinación habilita un procesamiento mixto escalar‑vector‑matricial muy eficiente en memoria.
Cada cluster XM Gen 2 puede entregar hasta 64 TFLOPS en FP8 a 2 GHz, y el diseño está pensado para apilarse en configuraciones multi‑cluster que superan en conjunto los 4 PFLOPS. Este enfoque modular facilita componer aceleradores a medida destinados a datacenters con diferentes perfiles de consumo y rendimiento.
SiFive subraya, además, que XM Gen 2 está fuertemente tuneado para LLMs y mantiene la tradición de la casa en rendimiento por vatio. La integración estrecha de los tres dominios de cómputo (escalar, vector y matriz) permite aprovechar un ancho de banda de memoria muy eficiente y minimizar copias y movimientos de datos redundantes.
Para los equipos que necesiten una base sobre la que construir aceleradores personalizados, XM Gen 2 actúa como blueprint listo para licenciar: los bloques X390 Gen 2 aportan control y vectorización potente, mientras que el motor matricial escala el throughput donde hace falta densidad de MACs.
Interfaces VCIX y SSCI: acelerar sin fricción
La llegada de VCIX (Vector Coprocessor Interface Extension) y SSCI (Scalar Coprocessor Interface) es uno de los puntos diferenciales de esta generación. Ambas interfaces permiten a aceleradores y coprocesadores acceder de forma directa a los registros de la CPU, lo que reduce la pila de software intermedia, baja latencias y mejora la utilización global del subsystem de memoria.
En la práctica, esto se traduce en menos tiempo “pegamento” y más tiempo útil de cómputo: los equipos pueden acoplar aceleradores vectoriales o especializados sin reinventar la rueda, con protocolos estables y un camino de datos optimizado. Combinadas con la apertura de la SiFive Kernel Library, la fricción para llegar a prototipos funcionales cae de forma sensible.
Para cargas con fases de preprocesado, planificación y postprocesado (por ejemplo, pipelines de visión e inferencia), esta conexión directa a registros simplifica mucho la orquestación. Los núcleos RISC‑V pueden conducir el flujo con precisión mientras delegan “lo pesado” en coprocesadores que operan con la menor penalización posible.
Adopción de RVA23 y soporte de formatos emergentes
SiFive alinea sus IP con la especificación RVA23, clave para el futuro del software en RISC‑V orientado a IA. Este paso habilita de fábrica tipos de datos como BF16, MXFP8 y MXFP4, algo especialmente valioso cuando el mercado se mueve hacia precisiones mixtas y dinámicas.
El soporte de MXFP4 no es un capricho: ha sido escogido por OpenAI para la distribución de modelos open‑weight, con lo que disponer de aceleración directa a ese formato reduce conversiones y cuellos de botella en despliegues modernos. En inferencia a escala, cada ciclo y cada byte cuentan.
La compatibilidad con RVV 1.0 en X280 y la ampliación de VLEN/DLEN en X390 aseguran que bibliotecas, compiladores y frameworks puedan exprimir con facilidad el hardware. Esto acelera la adopción en ecosistemas donde los ciclos de validación y mantenimiento del software son, por lo general, la parte más costosa.
Rendimiento, memoria y escalabilidad práctica
Una ventaja transversal de la familia Intelligence Gen 2 es cómo gestiona el ancho de banda y el movimiento de datos. La reconfiguración de cachés en X280 Gen 2 (adiós a L3, hola a un L2 compartido hasta 1 MB) y la combinación de ALUs vectoriales duales en X390 Gen 2 permiten sostener tasas elevadas sin caer en saturaciones tempranas.
El dato de hasta 1 TB/s en configuraciones de cuatro X390 Gen 2 ilustra bien la ambición del diseño: no basta con tener muchos FLOPS si no se alimentan de forma eficiente. En XM Gen 2, la integración vector‑matriz y la topología multi‑cluster refuerzan esa idea al minimizar hops y copias intermedias.
Para equipos de ingeniería, esto se traduce en soluciones que escalan “limpio”: se puede empezar con clusters pequeños para POCs y crecer hacia despliegues con varios clusters sin tener que replantear toda la arquitectura de datos y coherencia.
Casos de uso: del sensor al datacenter
En el extremo del edge, X160/X180 Gen 2 permiten aplicar IA en sensores inteligentes, control de vuelo de drones y robots móviles, donde los presupuestos de energía y coste por unidad son críticos. El soporte de INT8 y BF16, junto con registros vectoriales de 128 bits, acelera convoluciones, filtros y kernels de visión con gran eficiencia.
Un paso arriba, X280 Gen 2 encaja en gateways y sistemas embebidos que requieren más densidad vectorial, ya sea para analítica en tiempo real, preprocesado de datos en redes 5G/6G o funciones avanzadas en automoción. Su orientación a RVV 1.0 y la caché L2 compartida allanan el camino para pipelines de inferencia con baja latencia.
En la franja de alto rendimiento, X390 Gen 2 se presta a actuar como cerebro de aceleradores externos (ACU) o directamente como motor vectorial autónomo, con la ventaja de un camino claro para añadir coprocesadores mediante VCIX. Esto facilita montar soluciones híbridas donde el control y el cómputo pesado conviven de forma más eficiente.
Finalmente, XM Gen 2 pone la guinda para cargas a gran escala donde priman los TFLOPS por vatio y la facilidad para escalar. Al estar “muy afinado” para LLMs, resulta especialmente atractivo para inferencia de modelos grandes y para ciertas fases de entrenamiento ligero o ajuste fino en centros de datos.
Disponibilidad y hoja de ruta
SiFive ha confirmado que todas estas IP están ya disponibles para licenciar, lo que permite a los socios comenzar de inmediato su integración. En cuanto a productos comerciales, los primeros chips basados en estas IP se esperan en el segundo trimestre de 2026, un horizonte razonable para diseños complejos con certificaciones y validación exhaustiva.
Esta ventana temporal encaja con la demanda creciente prevista para edge y datacenter, y da margen a los equipos para madurar sus pilas de software apoyándose en la SiFive Kernel Library y en la estandarización de interfaces que propone la marca.
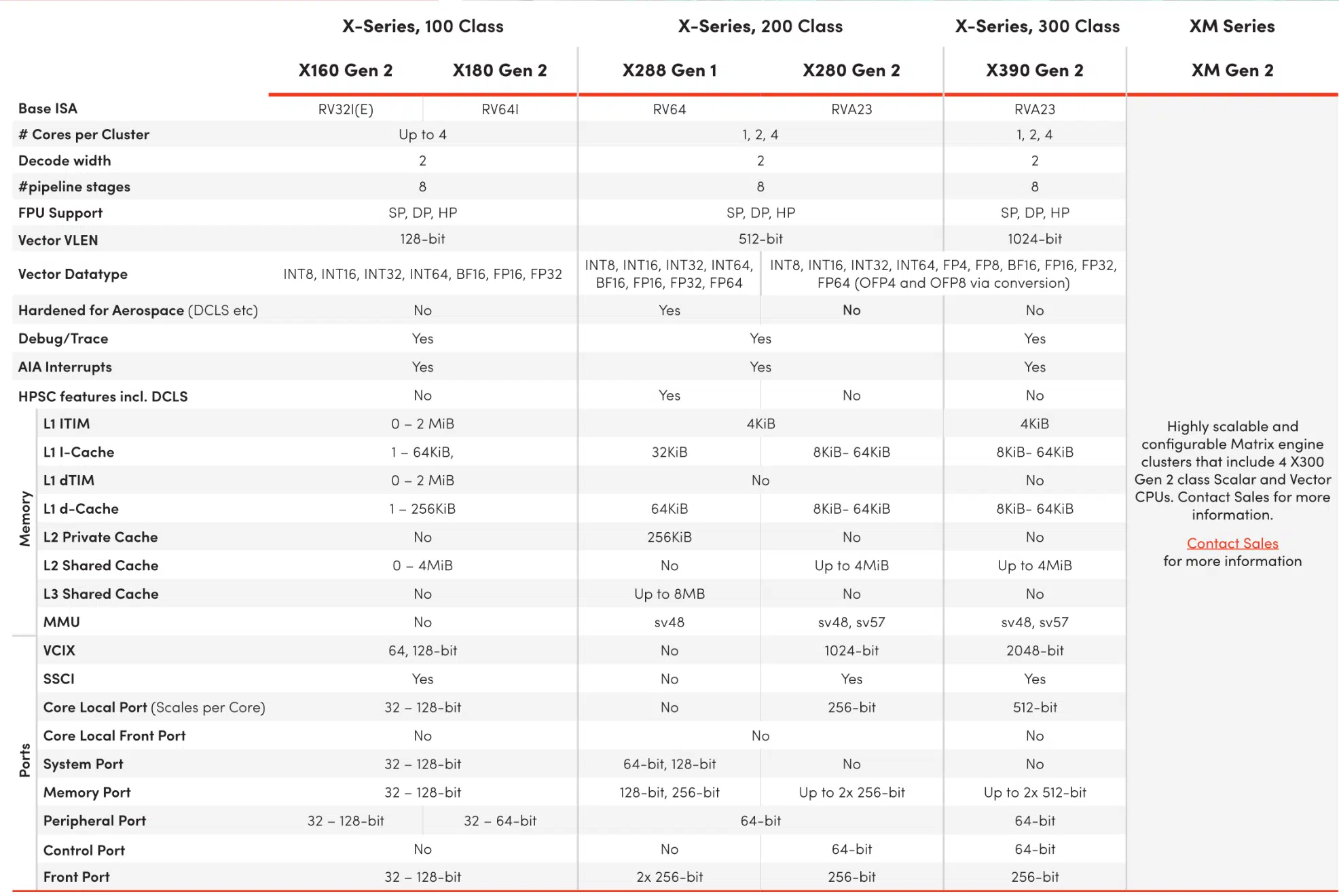
Resumen de especificaciones y rasgos clave
Para situar cada pieza en su sitio, conviene recordar los puntos más distintivos de la familia. El X160/X180 Gen 2 se orienta a bajo consumo con vectorización moderada; X280 Gen 2 refuerza el edge con RVV 1.0 y L2 compartido; X390 Gen 2 dispara el ancho vectorial y el paralelismo; y XM Gen 2 suma un motor matricial propio pensado para LLMs y escalado multi‑cluster.
- X160/X180 Gen 2: 32/64 bits, registros vectoriales de 128 bits, camino de datos de 64 bits, soporte de INT8 y BF16, clusters de 4, enfoque IoT/robótica con eficiencia máxima.
- X280 Gen 2: 8 etapas, dual‑issue, in‑order, superscalar; VLEN 512/DLEN 256; RVV 1.0 + SiFive Intelligence Extensions; jerarquía con L2 compartido de hasta 1 MB por cluster.
- X390 Gen 2: 8 etapas, dual‑issue, in‑order, superscalar; doble ALU vectorial; VLEN 1024/DLEN 512; escalable a 4 núcleos coherentes; VCIX opcional; hasta 1 TB/s en configuración de 4 núcleos.
- XM Gen 2: 4 × X390 Gen 2 + motor matricial SiFive; hasta 64 TFLOPS FP8 a 2 GHz por cluster; escalable por encima de 4 PFLOPS en multi‑cluster; muy afinado para LLMs y alto rendimiento por vatio.
Por qué importa ahora: software, estándares y ecosistema
Los anuncios de hardware son relevantes cuando vienen acompañados de software sólido y estándares. La adopción de RVA23, el soporte explícito de formatos como MXFP8/MXFP4/BF16 y la liberación de la SiFive Kernel Library apuntalan la propuesta para que bibliotecas y frameworks puedan sacarle jugo sin fricciones.
La apuesta por interfaces claras (VCIX y SSCI) también reduce el “factor riesgo” para quienes planean integrar aceleradores propios. En una época en que la diferenciación pasa por kernels específicos y modelos propietarios, tener un camino limpio a registros y rutas de datos de baja latencia marca la diferencia.
Sumado a la tracción previa en sectores como automoción, infraestructura y móvil, y a haber entrado en el ecosistema de grandes como Google, SiFive envía la señal de que RISC‑V ya no es solo una alternativa, sino una plataforma madura para cargas de IA de producción.
Todo esto, además, llega cuando los proveedores buscan autonomía tecnológica, costes sostenibles y flexibilidad de licencias. La receta modular de Intelligence Gen 2 encaja con ese deseo de construir exactamente lo que se necesita, ni más ni menos, y escalar cuando el negocio lo requiera.
Aunque cada caso de uso tendrá su propio diagrama de bloques, la coherencia de diseño entre X160/X180, X280, X390 y XM permite combinar piezas sin “sorpresas” y con una ruta evidente para optimizar rendimiento/consumo. Esa consistencia abre la puerta a ciclos de desarrollo más cortos y a menos re‑trabajo.
Vista en conjunto, la familia Intelligence Gen 2 cubre con solvencia el arco completo: desde el sensor que necesita IA básica hasta el rack que exige PFLOPS escalables, pasando por gateways y controladores que orquestan aceleradores externos. Es una jugada coherente con la tendencia del sector hacia arquitecturas heterogéneas y composable.
Quien busque cimentar una plataforma de IA moderna, tiene aquí bloques que combinan vectorización madura, cómputo matricial contundente y un ecosistema software que no parte de cero. Si a eso se le suma el empuje de estándares emergentes y la previsión de crecimiento en edge, el encaje de las piezas tiene bastante sentido.
SiFive coloca sobre la mesa hardware RISC‑V para IA que se siente práctico y bien pensado: configurable donde debe serlo, eficiente en lo que cuenta y con el puente al software cada vez más firme. Con licencias ya disponibles y primeras implementaciones de silicio previstas para 2026, es una propuesta con recorrido para construir hoy las plataformas de mañana.
