
StepFun AI Step-Audio 2 Mini es un modelo de voz de extremo a extremo que unifica comprensión, razonamiento y generación de audio en una sola arquitectura. Diseñado para conversaciones naturales y análisis profundo del habla, domina tareas como ASR, entendimiento paralingüístico, razonamiento sobre sonidos, traducción y diálogo voz a voz, reduciendo la latencia y minimizando alucinaciones gracias a llamadas a herramientas y recuperación multimodal.
Más allá de la teoría, Step-Audio 2 Mini brilla en benchmarks públicos y escenarios reales: entiende acentos y dialectos, capta emociones y prosodia, y es capaz de ajustar timbre, ritmo y estilo, incluso cantar o rapear. Además, se integra con búsqueda web y audio, y llega en abierto a través de GitHub y Hugging Face, lo que facilita probarlo, auditarlo y adaptarlo a necesidades de producto o investigación.
Qué es StepFun AI Step-Audio 2 Mini
En pocas palabras, es la versión compacta de la familia Step-Audio 2, un modelo multimodal de voz end-to-end preparado para producción que unifica tareas clásicas (ASR y TTS) con capacidades avanzadas de diálogo y herramientas. A diferencia del enfoque ASR + LLM + TTS por etapas, su diseño directo audio-audio/texto reduce complejidad y latencia, preservando detalles paralingüísticos (entonación, timbre, ritmo) y señales no vocales.
Entre sus pilares destacan: conversación inteligente con contexto largo y sensibilidad prosódica, Tool Calling nativo con RAG multimodal (texto y audio) para inyectar conocimiento actualizado y cambio de timbre según referencias recuperadas. Esta combinación disminuye alucinaciones y hace que las respuestas resulten más útiles y naturales.
La familia se completa con Step-Audio 2 (mayor capacidad) y componentes relacionados del ecosistema Step-Audio, incluyendo un modelo base de 130B parámetros empleado para preentrenamiento contextualizado con audio y un TTS eficiente (Step-Audio-TTS-3B). Aunque Mini no exige la infraestructura masiva del 130B, hereda su pipeline de datos generativos y las pautas de control fino de la voz.
Arquitectura y claves técnicas
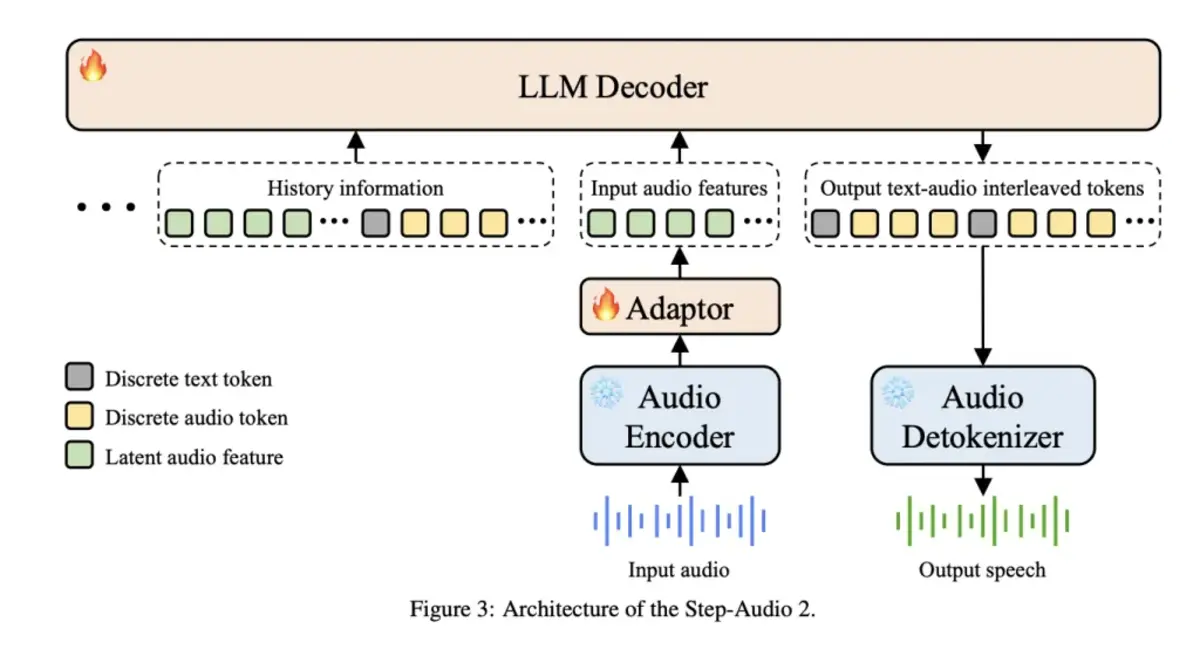
El sistema adopta tokenización dual e intercalada: un codebook semántico de 1024 entradas a ~16,7 Hz y otro acústico de 4096 a ~25 Hz, sincronizados con una relación temporal 2:3. Esta integración a nivel de token permite representar, a la vez, el contenido lingüístico y la textura sonora con más detalle.
Para la generación, se emplea un decodificador de voz híbrido que combina un modelo de flow matching con un vocoder mel-to-wave. Al entrenarlo con el esquema de doble codebook intercalado, el sistema conserva la inteligibilidad y la naturalidad del habla durante la síntesis, incluso cuando se controla emoción, velocidad o estilo.
La arquitectura en streaming se apoya en un Controlador que coordina VAD (detección de actividad de voz), tokenización de audio en tiempo real, el modelo lingüístico de Step-Audio y el decodificador. Incorpora generación especulativa (comprometiendo ~40% de tokens) y gestión de contexto basada en texto con compresión 14:1, lo que ayuda a mantener coherencia en diálogos largos con costes manejables.
En el entrenamiento posterior, se combinan SFT para ASR y TTS con refuerzo por retroalimentación humana (RLHF) y razonamiento de Chain-of-Thought focalizado en paralingüística. Esto mejora la capacidad del modelo para interpretar señales como emociones, tono o música y responder de forma matizada y controlable.
Descarga, instalación y uso local
El modelo está disponible en Hugging Face y el repositorio oficial, con scripts listos para inferencia y una demo web local. Los pasos de preparación del entorno (conda + pip) y la descarga con Git LFS son directos y, en equipos modernos, rápidos de replicar.
conda create -n stepaudio2 python=3.10
conda activate stepaudio2
pip install transformers==4.49.0 torchaudio librosa onnxruntime s3tokenizer diffusers hyperpyyaml
# Repositorio y pesos
git clone https://github.com/stepfun-ai/Step-Audio2.git
cd Step-Audio2
# Modelos en Hugging Face
git lfs install
git clone https://huggingface.co/stepfun-ai/Step-Audio-2-mini
Para realizar una primera prueba, basta con ejecutar el script de ejemplo: la inferencia funciona con audio y texto y permite validar la configuración del entorno sin complicaciones.
python examples.py
También hay una demo web local con interfaz simple que se levanta con Gradio, ideal para evaluar interacción por voz en un navegador.
pip install gradio
python web_demo.py
Demostraciones en línea, consola y app móvil
StepFun ofrece una consola de tiempo real para probar el modelo desde el navegador, así como un asistente móvil con búsqueda web y de audio integradas. En la app, basta con descargarla desde la tienda, abrirla y tocar el icono del teléfono en la esquina superior derecha para activar el modo voz.
La comunidad puede unirse a un grupo de WeChat mediante QR para debatir, compartir resultados y resolver dudas. Y si lo prefieres, los enlaces directos para descarga son estos: GitHub (Step-Audio2), Hugging Face (Step-Audio-2-mini) y ModelScope (modelo homónimo). En algunos listados externos verás avisos de cookies o mensajes de compatibilidad del navegador (como en Reddit o X), algo normal en plataformas sociales.
- GitHub: https://github.com/stepfun-ai/Step-Audio2
- Hugging Face: https://huggingface.co/stepfun-ai/Step-Audio-2-mini
- ModelScope: https://www.modelscope.cn/models/stepfun-ai/Step-Audio-2-mini
Rendimiento en benchmarks: comprensión, paralingüística y más
En pruebas públicas y de casa, Step-Audio 2 Mini y su hermano mayor muestran resultados de referencia. A continuación, repasamos los puntos clave comparados con sistemas comerciales y open source: GPT-4o Audio, Qwen-Omni/Qwen2.5-Omni, Kimi-Audio, Omni-R1, Audio Flamingo 3, Doubao LLM ASR, entre otros.
ASR multilingüe (tasas CER/WER más bajas son mejores)
En inglés, el promedio WER sitúa a Step-Audio 2 en 3,14 y a 2 Mini en 3,50, con conjuntos como Common Voice, FLEURS, y LibriSpeech (clean/other). Destaca LibriSpeech «other» con 2,42 para Step-Audio 2, por debajo de alternativas abiertas y comerciales. En chino, promedia 3,08 (Step-Audio 2) y 3,19 (Mini), con buenos resultados en AISHELL/AISHELL-2, KeSpeech y WenetSpeech.
Para escenarios multilingües adicionales, brilla en japonés (FLEURS) con 3,18 (Step-Audio 2) y 4,67 (Mini), y compite en cantonés (Common Voice yue). En conjunto “in-house” con acentos y dialectos chinos, el promedio cae a 8,85 (Step-Audio 2) y 9,85 (Mini), con mejoras claras en dialectos exigentes como shanghainés (17,77 vs 19,30 frente a otras opciones que superan 58).
Entendimiento paralingüístico
En la suite StepEval-Audio-Paralinguistic, Step-Audio 2 alcanza 83,09 de media y 2 Mini 80,00. Por dimensiones: género y edad llegan a 100/96 (2) y 100/94 (Mini); timbre 82/80; escenario 78/78; emoción 86/82; ritmo 86/68; velocidad 88/74; estilo 88/86; y vocal 68/76. El salto frente a sistemas previos demuestra control prosódico fino y robustez perceptiva.
Razonamiento y comprensión de audio (MMAU)
En el benchmark MMAU, Step-Audio 2 lidera con 78,0 de media (83,5 en sonido, 76,9 en voz, 73,7 en música), mientras que 2 Mini marca 73,2. Entre los comparados: Omni-R1 77,0, Audio Flamingo 3 73,1, Gemini 2.5 Pro 71,6, Qwen2.5-Omni 71,5 y GPT-4o Audio 58,1. Esto evidencia un razonamiento auditivo competitivo incluso frente a alternativas comerciales.
Traducción de voz
En CoVoST 2 (S2TT), las medias ascienden a 39,29 para Step-Audio 2 Mini y 39,26 para Step-Audio 2, con mayor fortaleza en inglés→chino (~49). En CVSS (S2ST), Step-Audio 2 lidera con 30,87 de media y Mini logra 29,08; GPT-4o Audio ronda 23,68. En conjunto, estos resultados consolidan la competencia cruzando idiomas en texto y habla generada.
Tool Calling nativo
En StepEval-Audio-Toolcall (búsqueda de audio, fecha/hora, tiempo y web), Step-Audio 2 logra altas precisiones/recalls de disparo y 100% en identificación de tipo/parámetros cuando aplica. Por ejemplo, en búsqueda de audio, su disparo promedia 86,8/99,5; en web search, 88,4/95,5; y en clima, 92,2/100. Frente a un fuerte baseline (Qwen3-32B), mantiene equilibrios muy sólidos entre trigger, tipo y parámetros.
Conversación voz a voz (URO-Bench)
Para chino (básico/pro), Step-Audio 2 alcanza 83,32/68,25 y 2 Mini 77,81/69,57. En inglés, GPT-4o Audio consigue 84,54/90,41 en medias, pero Step-Audio 2 le sigue de cerca en comprensión y razonamiento (92,72/76,51 en U/R básicos y 64,86/67,75 en pro), mientras que Mini ofrece 74,36 de media básica, notable para un sistema end-to-end abierto.
Relación con Step-Audio (130B) y TTS 3B
El ecosistema Step-Audio incluye un modelo 130B que sirve de base textual, con preentrenamiento continuado contextualizado en audio y post-entrenamiento por tareas. Gracias a un motor de datos generativos, se sintetizan audios de alta calidad para entrenar y liberar públicamente un TTS eficiente de 3B (Step-Audio-TTS-3B) con control de instrucciones (emociones, dialectos, estilos) muy granular.
En ASR, frente a referencias como Whisper Large-v3 y Qwen2-Audio, las variantes Step-Audio Pretrain y Step-Audio-Chat registran CER/WER competitivos en Aishell-1/2, WenetSpeech y LibriSpeech. Por ejemplo, en Aishell-1, Step-Audio Pretrain llega a 0,87% CER; y en LibriSpeech test-clean, Step-Audio-Chat firma 3,11% WER, con Qwen2-Audio en 1,6% como referencia. Estas cifras reflejan que la tokenización discreta de audio puede igualar o superar enfoques de features ocultas en distintos conjuntos.
En TTS, las variantes Step-Audio-TTS-3B y «Single» muestran tasas de error bajas y similitud de locutor (SS) elevadas frente a FireRedTTS, MaskGCT y CosyVoice/2. En test-zh, por ejemplo, Step-Audio-TTS llega a 1,17% CER; en test-en, a 2,0% WER, con SS competitiva. Además, al evaluar generación desde tokens discretos, Step-Audio-TTS-3B logra 2,192% CER (zh) y 3,585% WER (en), con SS en torno a 0,784/0,742, valores que delatan claridad y estabilidad vocal.
Requisitos y despliegue
Para la familia Step-Audio completa, se recomiendan GPUs NVIDIA con CUDA. La configuración de referencia para Step-Audio-Chat (130B) es de cuatro A800/H800 80 GB. También se proporciona una Dockerfile para preparar el entorno y recomendaciones como usar vLLM con paralelismo tensorial para el 130B (teniendo en cuenta que la rama oficial puede no soportar todavía el modelo Step 1, y que se requiere una flash attention personalizada por la variante ALiBi empleada).
En el caso de Step-Audio 2 Mini, los requisitos son más contenidos y la inferencia local resulta viable para pruebas y prototipado. La demo web y los scripts de ejemplo facilitan validar la pila sin necesidad de orquestaciones complejas ni infraestructura distribuida.
Casos de uso y ejemplos prácticos
Step-Audio 2 Mini ya se ha mostrado capaz de detectar sonidos naturales y locuciones profesionales, controlar el tempo del habla bajo demanda, y realizar búsquedas en tiempo real para traer noticias de última hora. Ante dilemas filosóficos, convierte consultas abstractas en métodos y pasos claros, reflejando su potencia de razonamiento auditivo y verbal.
También hay ejemplos multilingües fluidos (chino, inglés, japonés), juegos de idiomas y expresiones idiomáticas tal como “It’s raining cats and dogs”, capaces de ser explicadas con sencillez y tono natural. Las muestras públicas incluyen control de velocidad (muy rápido/muy lento), demostrando que el modelo no solo entiende el contenido, sino que gobierna la prosodia a petición.
Licencia y citación
El código y los modelos del repositorio se publican bajo licencia Apache 2.0. El informe técnico asociado puede citarse como Step-Audio 2 Technical Report (arXiv: 2507.16632), con una autoría extensa encabezada por Boyong Wu y colaboradores, y afiliación de StepFun AI. Para más detalles, consulta la entrada de arXiv y el BibTeX oficial.
@misc{wu2025stepaudio2technicalreport,
title={Step-Audio 2 Technical Report},
author={Boyong Wu et al.},
year={2025},
eprint={2507.16632},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2507.16632}
}
Step-Audio 2 Mini ofrece una mezcla muy poco común de precisión ASR, comprensión paralingüística, razonamiento auditivo y síntesis natural, empaquetada en un marco end-to-end listo para despliegues prácticos; con herramientas, RAG multimodal y control de voz fino, se posiciona como una opción abierta, versátil y con resultados SOTA en varias tareas clave.